
From SEO to AXO
For two decades, getting a website noticed meant one discipline: SEO — search engine optimization. You wrote for the crawler, and the engine sent people to you.
That era is quietly widening. More and more, people do not search and click — they ask an assistant. They put a question to Claude, ChatGPT, Perplexity, Gemini, and the assistant reads the web on their behalf and reports back. The assistant is the visitor; the person never sees the page.
So there is a second discipline now, alongside SEO, and it is starting to have a name: AXO — Agent Experience Optimization. Where SEO tuned a page for a search engine, AXO tunes it for the agent that reads and acts on a person’s behalf — it is to agents what UX is to people. (You will also see GEO and AEO, generative- and answer-engine optimization. Those are narrower — mostly about getting quoted inside an AI answer. AXO is the broader thing: a site an agent can actually use.)
The shift is not subtle if you look at server logs. AI-crawler traffic — GPTBot, ClaudeBot, PerplexityBot, and a long tail of less polite cousins — is now a meaningful share of inbound requests on most sites. The behaviour has changed before the vocabulary caught up.
What is at stake for a business
Three concrete things sit downstream of an AXO investment, each worth its own line on a budget.
Accuracy and attribution. When an agent has a clean way to read your site, it quotes you correctly and links back to the right page. When it does not, it scrapes — and what comes out the other end is whatever survived the scrape. A confident paraphrase of your work, in another assistant’s answer, with no link back to you, is worse than no mention at all. Your work is being talked about; the only question is whether the credit lands at your door.
A new discovery channel. A growing share of what used to be “search” now happens inside an assistant. People ask substantive questions there that they never typed into Google. A site an agent can read cleanly gets surfaced in those answers; one it struggles with gets skipped — and the prospect never knows you existed. The traffic is real, the attribution is different, and very few sites in your category are likely paying attention to it yet.
A window where being early still counts. AXO standards are still settling. The companies that adopt them now show up disproportionately in the AI answers people are starting to trust. Two years from now this will be ordinary practice; today it is a quiet edge.
What AXO actually looks like
Three plain things, in increasing order of effort. None of them are exotic.
A guide file. llms.txt is a small plain-text file at the root of a site — a sibling of the long-familiar robots.txt. It tells an agent, in plain language, what the site contains and where the important pages are. A few hundred words, hand-written, kept current.
Clean structure. Proper headings, semantic HTML, schema.org markup, sensible URLs. Most sites already have most of this. AXO is largely about not undoing it — about keeping your site readable rather than burying everything in client-side JavaScript an agent cannot run.
An ask interface. This is the substantive step, and the part most “AI SEO” advice skips. Rather than leave an agent to scrape and guess, your site offers a small, standard way to be asked — “find me the pages about X” — and to return the actual relevant passages, with links. The emerging standard is the Model Context Protocol (MCP). It is to AI agents roughly what a power socket is to appliances: an agreed-on shape, so things connect without special-casing. An agent that plugs in can search your writing and quote it accurately, instead of inventing a paraphrase from a scrape.
We built it on our own sites first
Before recommending this to anyone, we ran the full pattern on the jueewo ventures family — jueewo.ventures, aipokit.com, yawninghero.com. Three sites, one shared MCP server at mcp-sites.yawninghero.com, 78 articles and pages indexed. Every claim that follows comes from the implementation, not a slide deck.
The straightforward test: connect Claude Desktop (or Claude Code) to the server, then ask it a question that requires reasoning across multiple pages on multiple sites. We picked one with genuine depth in our corpus:
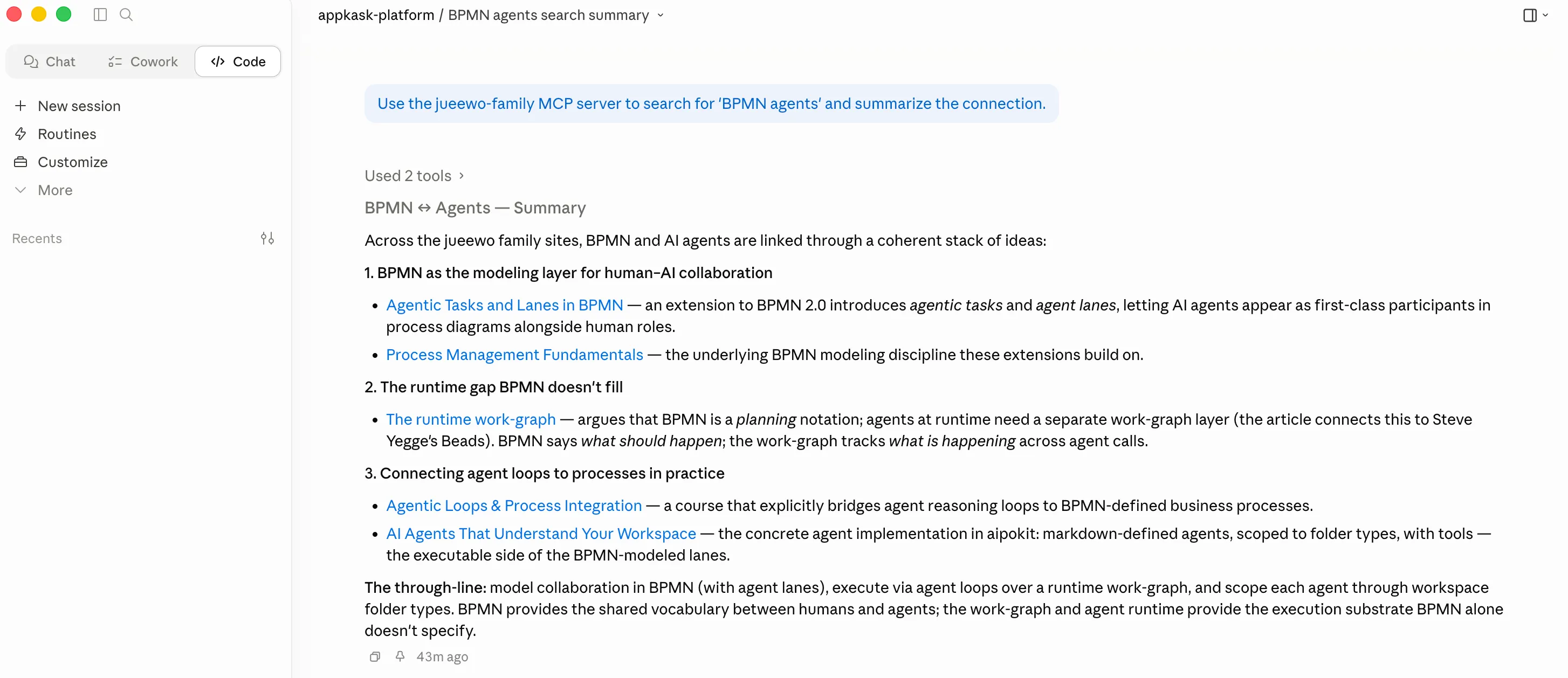
“Use the jueewo-family MCP server to search for ‘BPMN agents’ and summarize the connection.”
What the assistant produced — without rendering a single page of HTML — is reproduced verbatim below. The structure is its own; the content is ours.
BPMN ↔ Agents — Summary
Across the jueewo family sites, BPMN and AI agents are linked through a coherent stack of ideas:
1. BPMN as the modelling layer for human–AI collaboration. A BPMN 2.0 extension introduces agentic tasks and agent lanes, letting AI agents appear as first-class participants in process diagrams alongside human roles. Process Management Fundamentals is the underlying modelling discipline these extensions build on.
2. The runtime gap BPMN doesn’t fill. The runtime work-graph argues that BPMN is a planning notation; at runtime, agents need a separate work-graph layer (drawing the parallel to Steve Yegge’s Beads). BPMN says what should happen; the work-graph tracks what is happening as agents execute.
3. Bridging modelling and execution in practice. Agentic Loops & Process Integration connects agent reasoning loops to BPMN-defined business processes. AI Agents That Understand Your Workspace is the concrete aipokit implementation: agents defined as markdown files, scoped to folder types, equipped with tools — the executable counterpart to BPMN’s agent lanes.
The through-line: model collaboration in BPMN with agent lanes → execute via agent loops over a runtime work-graph → scope each agent through workspace folder types. BPMN supplies the shared vocabulary between humans and agents; the work-graph and agent runtime supply the execution substrate BPMN itself does not specify.
Two screenshots from the session itself — the assistant’s synthesis sitting on top of a single MCP search call. Between the first run and the second we shipped a small change to the server: results that came back as a flat list now arrive grouped by source kind, so the structural shape of the corpus reaches the model directly rather than being inferred from URL patterns.
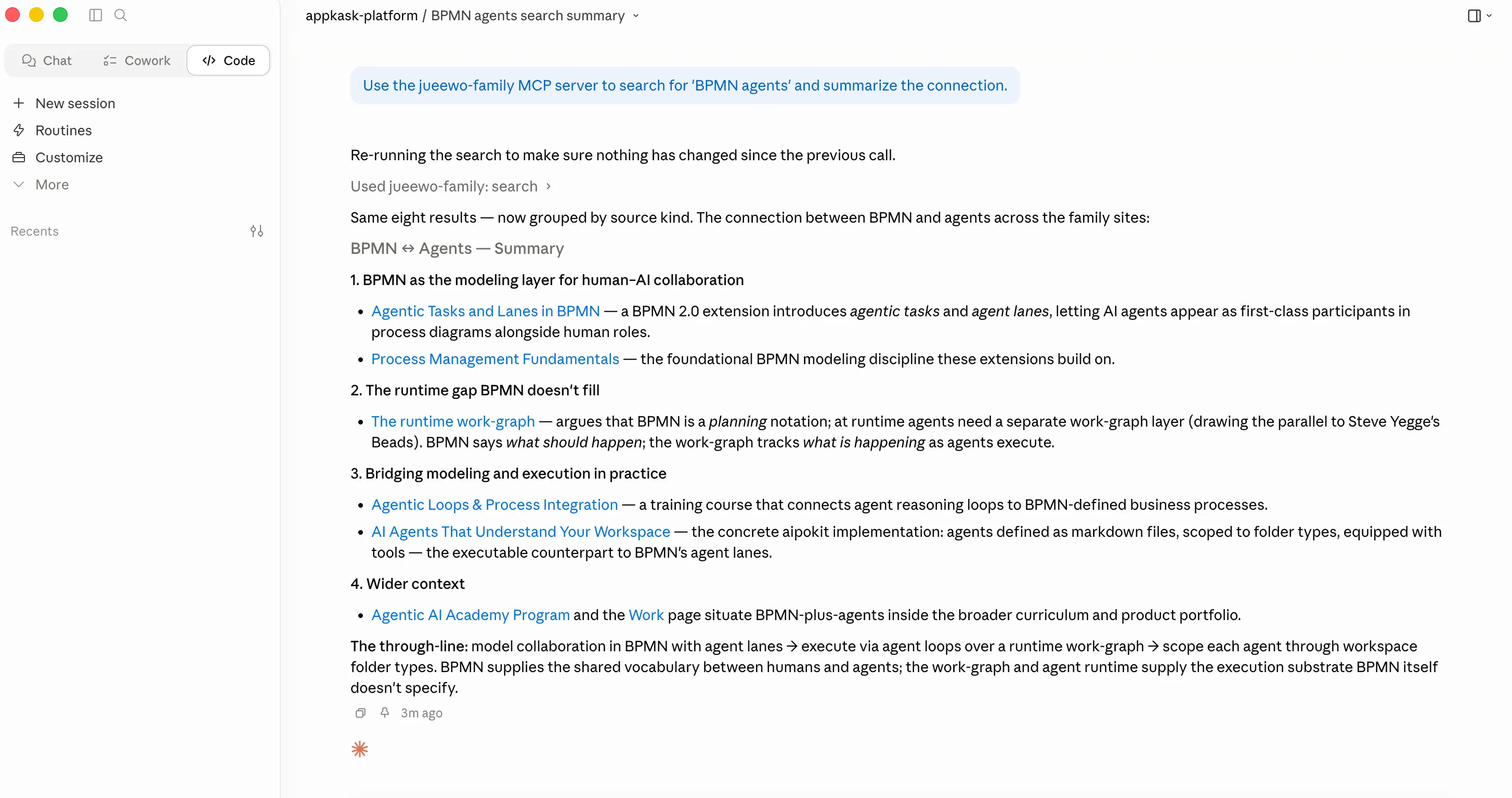
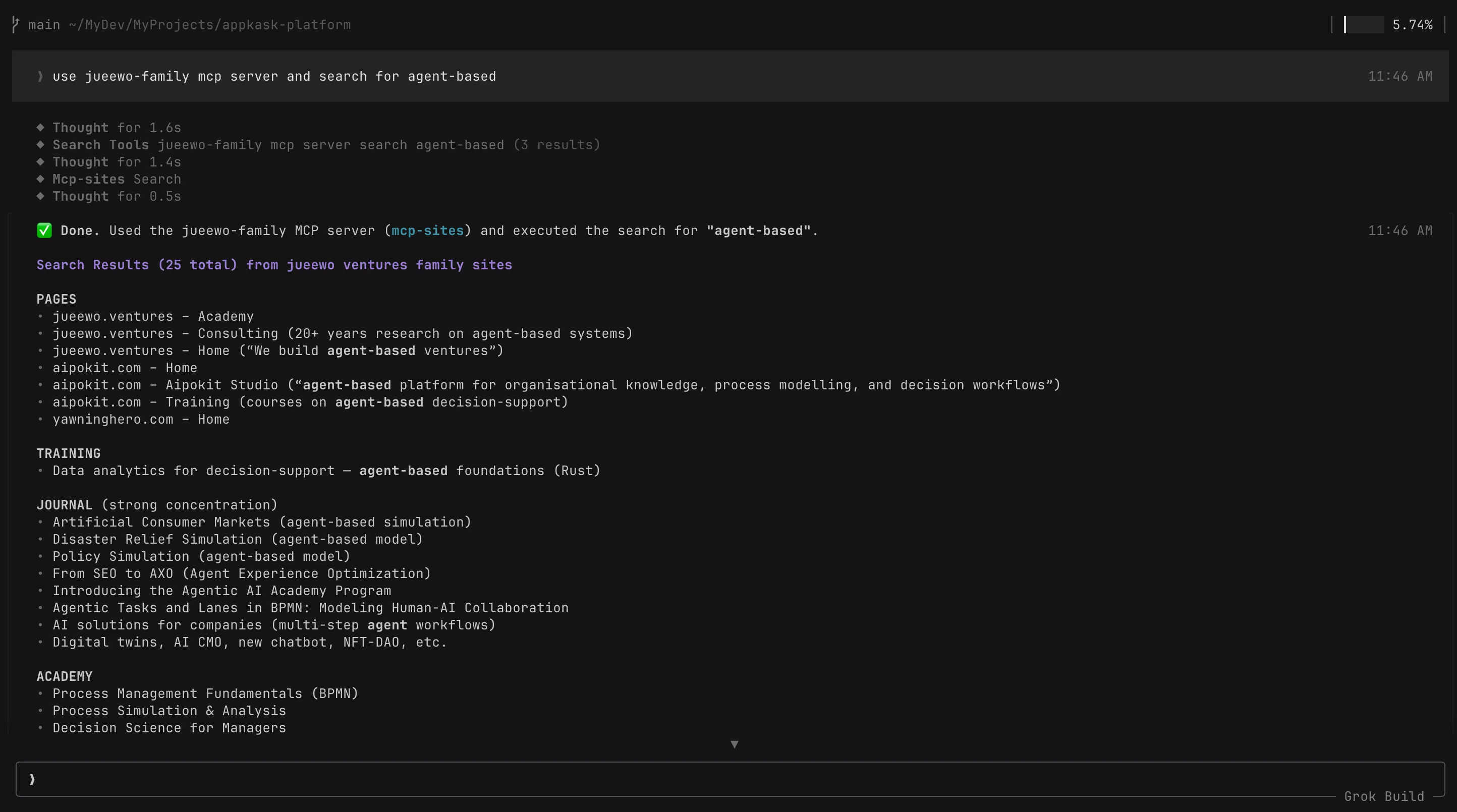
And the assistant itself is not the point — the protocol is. The third screenshot below is the same MCP server called from a different vendor entirely: Grok, via xAI’s Build mode. Same server, same answers, different assistant. An AXO investment is not a bet on Claude or any single model; it works wherever an MCP client lives, and the field is converging on that quickly.
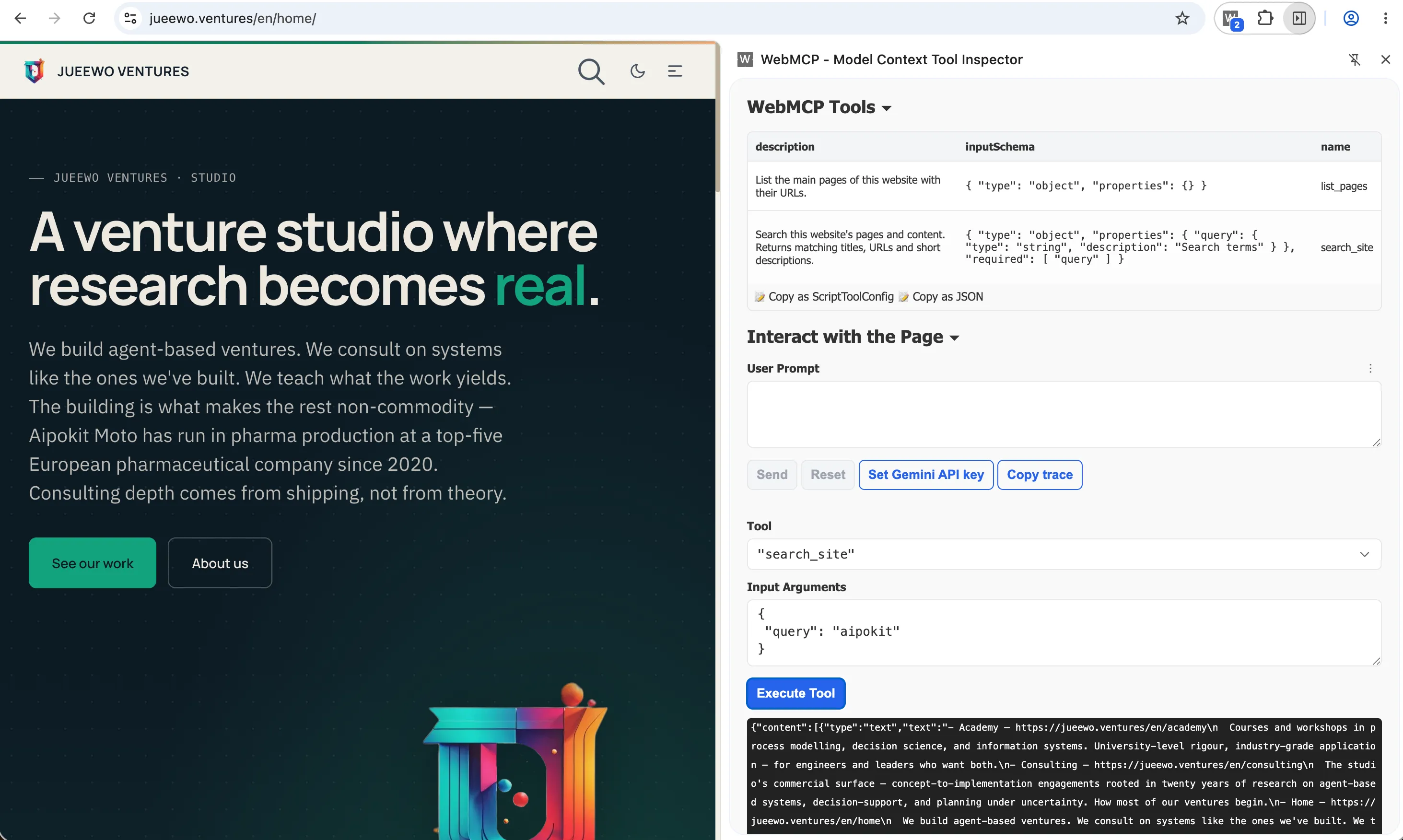
And there is one more AXO surface worth showing — structurally different from the server-side pattern above. WebMCP lets a page expose its own tools to an assistant running inside the visitor’s own browser. Instead of an external Claude or Grok calling our shared MCP server from somewhere else on the internet, the visitor’s own browser-assistant calls tools the page itself declares, right while the person is on it. The screenshot below shows a WebMCP inspector on jueewo.ventures listing the tools — list_pages, search_site — that the page advertises. Two complementary patterns sit side by side: external agents reach the shared MCP server; in-browser assistants reach the page directly.
Several things in those synthesis runs are worth noticing.
It cites five distinct sources across two sites — four journal articles and one product update — and a training course as supporting context. Every name in italics is a real page on one of our sites.
It synthesises a through-line the individual articles never state in those words (“BPMN says what should happen; the work-graph tracks what is happening”). That synthesis is only possible because the model had clean, structured access to the corpus at once. A scraper would have produced a montage of paragraphs; the assistant produced an argument.
It distinguishes article from training course from product update — the structural shape of the corpus is visible to the model, not inferred from URL patterns.
This is what AXO delivers in practice. Not “show up in an AI answer”, which is too small a frame, but: an agent reasoning over your published work as a first-class source, citing it, building on it, connecting it.
When meaning beats matching
A live demonstration of why an ask interface is more than search with better typography. Below is the same query — “helping organisations adopt AI safely” — run twice against the same MCP server, the same content, the same instant. Only the ranking method differs.
Keyword search ranks by literal word overlap. It returns, in order:
- Sailing — a working week at sea for senior leaders.
- Aipokit Studio — an agent-based platform for organisational knowledge.
- Training — a catalogue of courses on agent-based decision-support.
- Introducing the Agentic AI Academy Program.
- Agentic Tasks and Lanes in BPMN.
The Sailing page is a five-day strategy retreat by the Adriatic. The query is about AI safety. The page mentions “organisational problem” once. Keyword search has no way of knowing those two things are not the same — and an LLM consuming the result list dutifully puts Sailing first in its answer, with a citation, recommending a sailing week as the way to adopt AI safely. Confident, polite, wrong.
Semantic search ranks by what the query means. Same query, same content, same server:
- Agentic AI in the Enterprise — “Strategy, governance, and organizational readiness for deploying AI agents at scale.”
- AI Agent Security, Privacy & Alignment — “Secure agentic AI systems — data protection, access control, alignment, and compliance.”
- Building Agentic Workflows — “Design, implement, and deploy AI agent systems for real business processes.”
- Agentic Loops & Process Integration — connecting agent reasoning loops to real business processes.
- AI Agent Data Pipelines & Knowledge Systems — the data infrastructure that makes agents useful.
Every one of those is a real answer to the question. None of them contains the words “helping”, “organisations adopt”, or “safely” literally. The model recognises that enterprise readiness, security, alignment, and deployment workflows are what a serious version of the question is asking about.
The infrastructure cost of doing this right is not a different system. It is the same MCP endpoint. The change is internal: every indexed document carries a small vector (384 numbers) computed locally at build time, and the server compares vectors at query time. ~50 ms per question, no extra vendor, no per-query bill, no opaque algorithm. The model that does the work is small, open, and runs in the same process that serves the answers.
The reason this matters is the asymmetry it creates. A keyword-only AXO surface is technically AXO — an agent can read it — but it gives the assistant the wrong pages and the assistant confidently misrepresents you. A semantic-aware surface gives the assistant the pages a smart human would have sent, and the answer it writes is the one a serious prospect would actually trust. Same site, two different reputations, depending on which layer of AXO you stop at.
What this means for your business
A few implications worth thinking through before deciding when to start.
Existing content compounds differently. A library of well-written articles is more valuable in 2026 than it was in 2024 — because agents can now actually find and use them. Most of the work for AXO is exposure, not authoring. If you have invested in content marketing over the last five years, AXO is the layer that lets that investment continue to earn after the search-engine era has thinned.
Attribution becomes infrastructure. When an LLM quotes you and links back, you stop competing only for clicks and start competing for citations. That is a different game with different metrics. AXO endpoints are themselves instrumented — every agent query can be logged, so you know whether agents are finding you, what they ask for, and which pages they actually use. SEO told you who clicked; AXO tells you what an assistant chose to synthesise from. The latter is closer to brand equity than to traffic.
Industries change at different speeds. B2B knowledge-services — consulting, technical software, training, research-heavy services — are seeing the fastest agent-mediated discovery, because the people who use assistants substantively tend to ask substantive questions. Consumer brands and visual-first categories lag (for now). Do not wait for the category average; look at how your own prospects ask questions when they are serious.
Cost is asymmetric. The static, content-led sites that benefit most from AXO are also the cheapest to upgrade. The work is mostly additive — a guide file, a small ask-server, some structured-data tightening. For a site that is already statically published, a competent week of work is typically enough. For a heavier site, the conversation is about which content surfaces to expose, not “rebuild the whole thing”.
What we can do
We did this work on our own sites first, deliberately, so we could speak about it from experience rather than from a deck. The implementation is open; the architecture is standard; the standards are public. None of it is a moat. The value we add is judgement about which parts matter for your situation, and the time and craft to do them well.
Three ways we typically engage:
- Assessment. A one- to two-week audit of an existing site: what is already AXO-ready, what is not, what to fix first, what to skip. A concrete report you can act on (or hand to another team). No upsell.
- Implementation. Adding the AXO layer to a live site — any stack — or building the shared-server pattern across a family of sites for an organisation that has several. We can run the project, or we can hand it to your engineering team and consult while they ship.
- Workshop and advisory. A half-day or full-day session for a marketing-plus-engineering team that wants to do the work themselves, using our reference implementation as the starting point. We bring the playbook; you bring the site and a working session.
If you would like to discuss any of these, contact@jueewo.com reaches us directly. If you would rather watch the field settle for another quarter, also legitimate. The window is open; it is not closing tomorrow.
A few questions
Does this change the sites for human visitors? No. The AXO layer is additive. The pages a person reads stay the same — same speed, same design, same content. Agents see a parallel surface that humans never visit.
Won’t AI just be trained on our content anyway, eventually? Training is a one-time, stale snapshot — months out of date by the time a model ships, and undifferentiated from everyone else’s content in the same dataset. AXO is live: an agent asking your MCP server tonight gets what you published this afternoon, attributed to you, with a link back. The two are not substitutes. AXO is to training-time scraping what a phone call is to a transcript from a year ago.
How do you measure whether it works?
The same way you measure SEO traffic, but for a more interesting metric: not “who clicked”, but “which agents chose to use our content in a synthesis, for which questions”. The MCP server logs every agent query. The on-site llms.txt and agent-index.json show up in access logs. The picture you build over a quarter tells you which of your topics agents are reaching for, and which assistants are sending agents.
Is “AXO” just chasing AI hype?
We have tried to keep it modest. We adopted open, published standards — llms.txt, MCP, schema.org — the way one adopts a sitemap. If a piece stops earning its place, we drop it. AXO is a useful name for a real shift, not a product we are selling.
Can I see how it works? You just did. The transcript above is the actual output of an assistant calling our MCP server. A more technical companion post — architecture, choices, what worked, what we would change — is the next piece in this series.
Should we wait until the standards finish settling?
The risk of waiting is asymmetric. Standards converge by adoption; the sites that participate now shape what wins. The downside of moving early is small — the work is mostly additive, the standards are intentionally simple, and migrating from llms.txt v1 to v2 (when that arrives) is a text edit. The downside of waiting is being invisible to assistants for the period during which their use is growing fastest.